Domain spoofing works because people trust familiar names before they verify them. That moment of recognition can make a false identity feel legitimate. Attackers can borrow credibility they never earned, and misplaced trust becomes harder to catch before harm follows.
Key Takeaways
- Domain spoofing spans email header forgery, look-alike domain registration, DNS poisoning, and ad bid-request manipulation. Each layer requires its own defenses.
- SPF, DKIM, and DMARC work together to protect email sender identity, but only when they are enforced and aligned with the visible From address.
- Attackers increasingly deliver spoofed domains through SMS and QR codes, which bypass email-based authentication controls entirely.
- Effective protection depends on matching each impersonation technique to the right control rather than relying on any single protocol or user habit.
What Is Domain Spoofing?
Domain spoofing is the falsification of a domain name identifier to make a communication, website, or ad placement appear to originate from a trusted source when it does not.
Why Trust in Domain Names Is the Core Vulnerability
Every interaction online begins with a name. You may see a sender address, a browser URL, a domain in a text message, or a publisher name attached to an ad. Domain spoofing targets that moment of recognition by manipulating the identifier so it reads as something familiar. A spoofed domain inherits whatever goodwill the real brand has built. This lowers the target's skepticism and raises the attack's success rate. When a spoofed domain tricks a customer into entering credentials on a fake site, the damage falls on both the victim and the impersonated brand. The attack erodes a trust relationship that neither party chose to put at risk.
What Are the Main Types of Domain Spoofing?
Each domain spoofing type exploits a specific protocol weakness at a different point in the chain between sender and recipient.
Email Header Forgery and Look-Alike Domain Registration
Simple Mail Transfer Protocol (SMTP) was originally designed without built-in sender authentication. Every email carries two "From" identities: the envelope sender, used during message transit, and the header "From" field, displayed to the recipient. An attacker can set the visible "From" to any domain while using their own envelope sender. This gap between the transit identity and the display identity is the root vulnerability that SPF, DKIM, and DMARC were built to address. Without authentication records published by the real domain owner, the receiving server has no reliable way to distinguish a legitimate message from a forged one.
Instead of forging headers, other attackers register domains that visually resemble a target brand by adding or swapping characters, including Unicode glyphs that render identically to ASCII letters. Because these are legitimately registered domains, they can publish their own valid email authentication records. Paired with a cloned version of the legitimate site, these look-alike domains capture credentials from visitors who do not notice the altered URL.
DNS Poisoning and Ad Bid-Request Manipulation
DNS resolvers cache responses from upstream servers, but the baseline protocol provides no cryptographic way to verify those responses, a weakness NIST has documented in its DNS security guidance. An attacker who injects a forged response into a resolver's cache can redirect users to a malicious IP address, even though the user typed the correct domain. DNSSEC is a structural countermeasure because it adds cryptographic signatures to DNS records and allows validating resolvers to verify DNS responses.
In real-time bidding, every ad impression opportunity arrives as a bid request containing metadata about the publisher's domain. A fraudster operating a low-quality site can overwrite the domain field to claim the impression belongs to a premium publisher. Demand-side platforms bid at premium rates based on falsified metadata. Industry standards like ads.txt and sellers.json let buyers verify seller authorization before bidding. Cross-referencing the OpenRTB SupplyChain object with these records gives buyers a way to confirm whether a bid request is actually authorized by the declared publisher.
Why Look-Alike Domains Fool People So Easily
Look-alike domains work because people do not reliably catch small character-level differences in domain names, especially on mobile screens or when reading quickly.
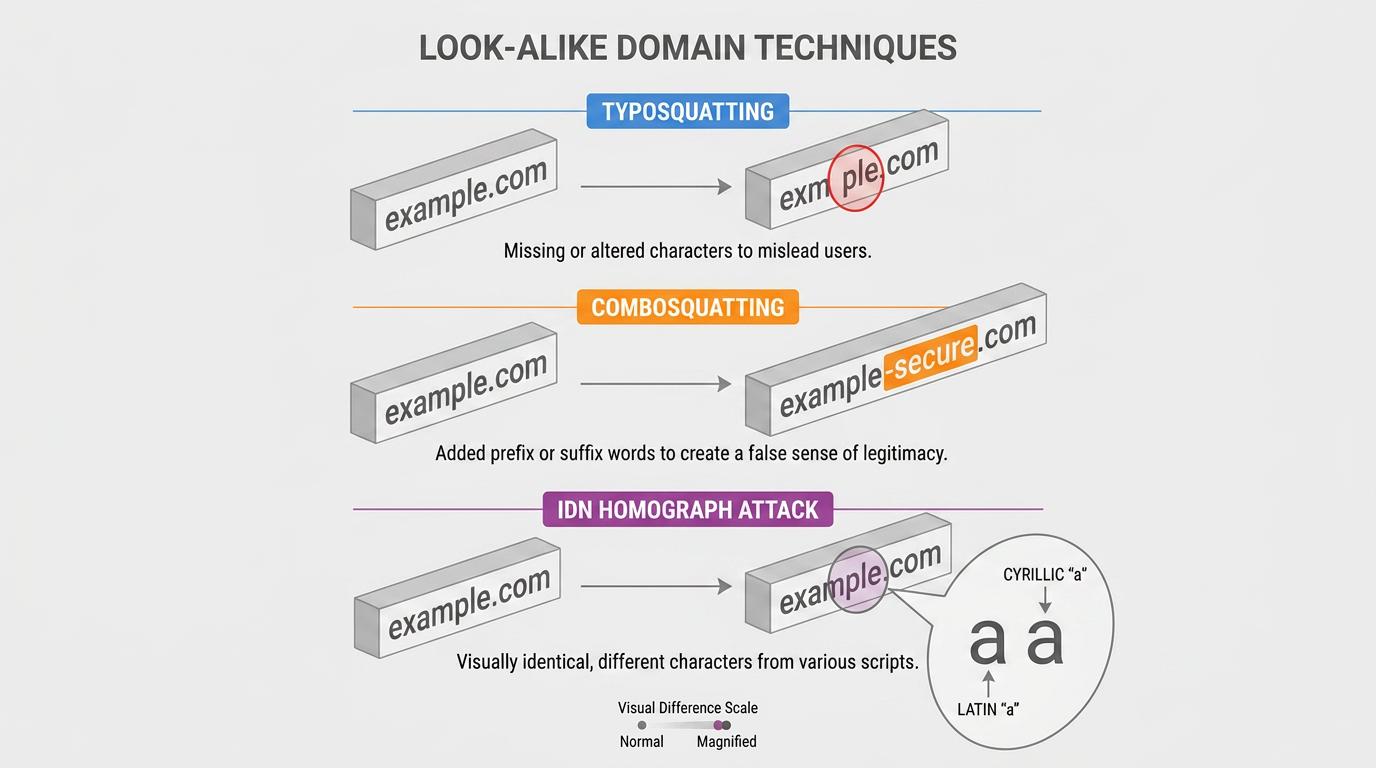
Typosquatting, Combosquatting, and Homograph Techniques
Typosquatting relies on registering domains with common misspellings or character additions targeting popular brands, such as doubled letters or adjacent-key substitutions. Related variants include combosquatting and bit-squatting. The relatively low cost of domain registration can make typosquatting an accessible entry point for domain-based attacks.
Internationalized domain name homograph attacks add a different dimension. These attacks use Unicode characters from different scripts that are visually identical to Latin letters. A Cyrillic "a" and a Latin "a" look the same in most fonts but are different Unicode code points. An attacker can register a domain where one or more characters are drawn from a non-Latin script, and the result renders identically to the real domain. Browser mitigations exist for IDN homograph attacks, including mixed-script and policy-based defenses, but peer-reviewed comparative studies have found that major browsers still have bypass opportunities. ICANN policy materials distinguish between top-level string rules for new gTLDs and separate rules for second-level domain registrations.
Visual Cues That Break Down in Practice
Users are commonly told to "check the URL carefully," but this advice has structural limits. Even on desktop, character combinations like "rn" and "m" or "vv" and "w" can be easy to miss at normal reading speeds, depending on the font and spacing.
The problem compounds when spoofed domains appear in QR codes, where the destination URL may not be obvious until after scanning. These perceptual limits, combined with the migration of spoofed domains into channels that lack any URL display, make protocol-level technical controls necessary.
How SPF, DKIM, and DMARC Reduce Domain Spoofing Risk
These three protocols form an email authentication trilogy that, together, addresses the sender verification gap in SMTP. Each one authenticates a different identifier, and none is sufficient alone.
SPF and DKIM Identifier Authentication
Sender Policy Framework lets a domain owner publish a DNS record listing the IP addresses authorized to send email on behalf of that domain. When a message arrives, the receiving server checks whether the connecting IP matches the SPF record for the envelope sender domain. The critical limitation: SPF validates only the envelope sender. The "From" address displayed to the user remains outside the SPF check. An attacker can pass SPF for their own domain while the visible "From" shows a completely different, spoofed domain.
DomainKeys Identified Mail adds a cryptographic signature to outgoing messages. The sending server signs headers and body content with a private key; the corresponding public key is published in DNS. The receiving server verifies the signature, confirming the message was authorized by the signing domain and was not altered in transit. DKIM authenticates the signing domain, which may differ from the visible "From" address. The same gap remains. On its own, each protocol leaves the visible address unverified.
DMARC Alignment and Its Boundaries
DMARC closes the gap that SPF and DKIM leave open. Published as a DNS record, DMARC requires that the domain authenticated by SPF or DKIM aligns with the "From" domain that users actually see. If neither produces an aligned pass, the receiving server follows the domain owner's published policy: monitor only, quarantine, or reject. Only quarantine or reject provides active spoofing protection.
CISA's Cross-Sector Cybersecurity Performance Goals recommend DMARC enforcement at p=reject in certain contexts but do not state that all corporate email infrastructure should run DMARC at reject. DMARC aggregate reports provide visibility into which IP addresses are sending mail under the organization's domain. They reveal both spoofing attempts and unauthorized legitimate senders. Even at full enforcement, these protocols protect only the exact domain for which they are published and have no relevance when spoofed domains arrive through SMS, QR codes, or social media.
How to Reduce Domain Spoofing Risk
Reducing domain spoofing exposure requires matching controls to attack layers rather than relying on a single technology.
Email and DNS Authentication at Enforcement
Publishing SPF, DKIM, and DMARC records is a baseline control for reducing domain spoofing, and organizations often work toward DMARC enforcement such as p=reject as their program matures. Organizations with multiple SaaS services sending on their behalf need to audit their SPF includes and ensure DKIM signatures are configured for every authorized sender. DMARC aggregate reports reveal unauthorized source IPs. Those IPs represent either active spoofing attempts or undiscovered legitimate sending infrastructure.
DNSSEC adds cryptographic signatures to DNS responses and protects against cache poisoning. A CISA directive directs federal agencies to audit DNS records, enable multi-factor authentication on all accounts capable of making DNS changes, and monitor Certificate Transparency logs for unauthorized certificate issuance. CT log monitoring can help detect when a TLS certificate is issued for a suspicious or look-alike domain. This gives the legitimate brand an opportunity to investigate and pursue revocation or takedown actions before the certificate is used more broadly.
Domain Monitoring, Takedowns, and Ad Fraud Controls
Proactive monitoring for newly registered domains that resemble an organization's brand is one of the most direct defenses against look-alike attacks. When a fraudulent domain is identified, organizations can report it through registrar abuse processes, and in trademark-related cases may also pursue action through ICANN's UDRP. Simulated phishing exercises and just-in-time training build recognition habits that reduce click-through rates on look-alike domains across email and messaging channels.
Organizations buying digital advertising can reduce ad fraud exposure by verifying ads.txt files before bidding and cross-referencing seller accounts against sellers.json records. Advertisers should verify that their demand-side platforms check authorization records on every bid request rather than treating ads.txt as an optional filter.
How Users Can Spot Domain Spoofing
Individual detection is unreliable on its own, but a few habits significantly reduce risk.
Practical Detection Habits and Their Limits
Before clicking a link, hovering over it reveals the actual destination. Extra characters, swapped letters, or unexpected subdomains are common indicators. In spoofed URLs, the brand name sometimes appears as a subdomain (brand.attacker.com) rather than as the primary domain.
A padlock icon confirms encryption only. Attackers can obtain valid certificates for spoofed domains. When in doubt, avoid clicking links in messages altogether and go to the expected site through a saved bookmark or a direct search. For financial requests received by email, verifying through a separate communication channel, such as a phone call to a known number, adds a layer of confirmation that no technical control can replicate.
Real-World Domain Spoofing Examples and Impact
Domain spoofing is behind some of the largest categories of financial cybercrime.
Business Email Compromise and Brand Impersonation Campaigns
Business email compromise (BEC) relies heavily on spoofed or impersonated sender domains to redirect payments and initiate fraudulent wire transfers. According to the FBI IC3 report, BEC generated over $3 billion in reported losses in 2025. These figures are based on complaints voluntarily submitted to IC3.
Threat actors have registered domains specifically designed to impersonate well-known brands. Attackers have used look-alike domains in phishing and intrusion activity, including to support initial access and follow-on access methods. Documented domain patterns (hservice[.]live, gscare[.]live, nhelpcare[.]info) show how look-alike domains can serve as first-stage components of malicious infrastructure used in IT help/support-themed social engineering and brand impersonation.
Where Domain Spoofing Is Evolving Now
The techniques behind domain spoofing are adapting as delivery channels shift and attackers use cheaper infrastructure with automated content generation.
New gTLD Abuse
Cheap registrations continue to fuel look-alike domain campaigns while the policy process moves slowly.
AI-Generated Lures and Non-Email Delivery Channels
Large language models accelerate phishing content generation and help less-experienced attackers craft more persuasive messages. When paired with a spoofed or look-alike domain registered in a cheap new gTLD, AI-generated content makes the overall deception harder for both users and automated filters to catch.
Domain spoofing is commonly associated with email, though phishing more broadly also occurs across channels such as SMS, messaging apps, and web-based impersonation. Attackers deliver spoofed domain links directly to phones and through QR codes, where users may have less visibility into the full destination URL and where phishing can arrive through channels beyond traditional email. SPF, DKIM, and DMARC have no relevance in SMS, so even organizations with fully enforced email authentication remain exposed through this channel. QR codes compound this gap by hiding URLs entirely until after scanning.
From Protocol Gaps to Layered Resilience
Domain spoofing works because trust in domain names is distributed across multiple systems, each with its own vulnerabilities. No single protocol or user habit covers all of these layers. The organizations and individuals who manage this risk most effectively are the ones who match each attack layer to the right control, then build outward from there.
