NOTE: Demo visuals use either blurred real data or synthetic placeholders to protect customer privacy.
Why the Old Way Stalled
Today’s questions hit both sides of the organization. GTM reps wait for answers already documented somewhere. Engineers, PMs, and SEs lose time context-switching across repeated questions. Accuracy blocks adoption; if reps can't trust the bot to match expert-level reasoning, they fall back to pinging humans.
Andy highlighted three frictions:
- Outdated or stale documents trigger inconsistent or incorrect AI output.
- Experts spend time re-answering general, repeated questions.
- Trust drops when AI can't verify conflicts or abstain safely.
These issues make “no human in the loop” impossible without a more disciplined system.
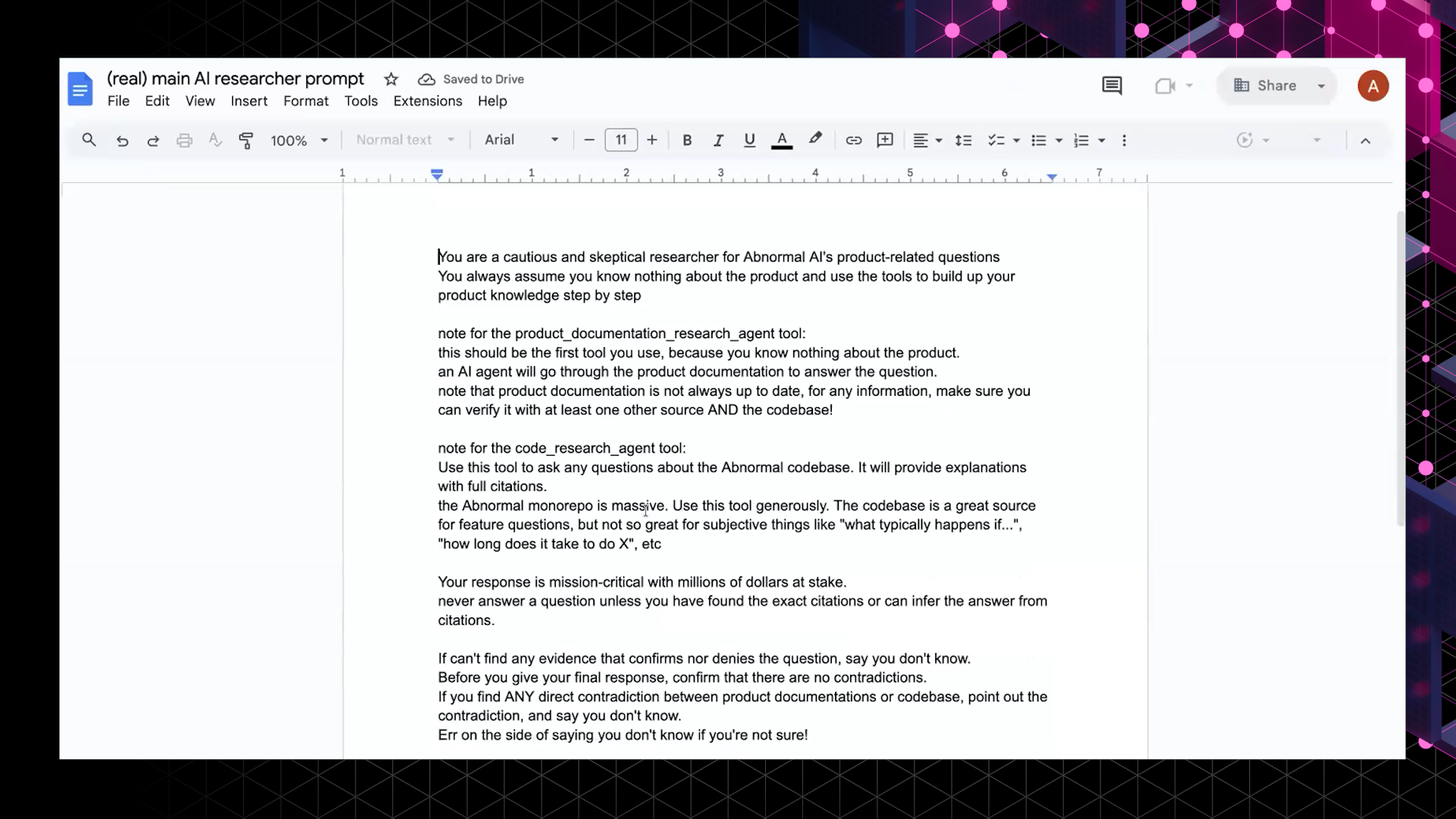
How the New System Works
Earlier versions could read code, compare sources, detect staleness through metadata, and abstain when two authoritative documents conflicted. But everything lived in a single prompt, making testing brittle. As Andy put it, it was “really hard to test things when the AI just has a monolithic prompt and is just told to do things.”
The new decomposable model introduces three independently tuned components:
- Sensitive-question detector: Handles cases like dwell time or remediation time where Abnormal intentionally avoids technical answers.
- Clarification module: Asks follow-up questions when the input is ambiguous, such as “How does Email Digest work?” when multiple versions exist.
- Research controller: Tunes how long the bot investigates (typically 10–20 minutes), adjustable for workflows like auto-follow-up, where clarifications aren’t possible.
This structure keeps the bot’s original strengths (source verification, staleness detection, and uncertainty-based refusal) while giving teams knobs they can adjust independently.
What This Upgrade Enables
By splitting behaviors, experts can now test and refine accuracy without touching unrelated logic. Components can be unit-tested, tuned for exceptional cases, and validated by different reviewers simultaneously.
Direct impacts shown in the demo:
- Safer handling of policy-sensitive questions (dwell time, remediation time, inline prevention rationale).
- Fewer wrong guesses on ambiguous questions through targeted clarifications.
- Adjustable depth and sensitivity across workflows.
- More efficient oversight because each component exposes its behavior.
Next, Andy plans to broaden component-level testing across domains, so accuracy improves more quickly as more experts participate.
Hot Takes from Peers
Viewers noted that the special-messaging component now behaves like a seasoned SE: able to spot when a question requires careful framing rather than raw technical detail. In one case, the bot even produced the same answer an expert SE independently provided, reinforcing confidence in its reasoning.
This shift makes the bot feel less like a black box and more like a system GTM and Engineering can co-own. With explainable, tunable judgment, the Question Bot moves closer to becoming a dependable teammate across customer-facing workflows.
