NOTE: Demo visuals include blurred data or synthetic placeholders to protect customer privacy.
Where Support Still Breaks
The customer experience today is still shaped by email and tribal knowledge. Andres called out a familiar pattern: knowledge is fragmented across people and internal systems, customers ping-pong back and forth to get answers, and they often end up with stale knowledge articles. Even when the underlying documentation exists, the path to a reliable answer is slower than it needs to be.
Three frictions stood out in this update cycle:
- Manual workflow by default: customers still rely on email threads to reach a resolution.
- Fragmented and aging knowledge: answers live across systems and people, and published articles can lag reality.
- No tight feedback loop: without consistent evaluation, it is hard to see what the bot resolves versus where it fails.
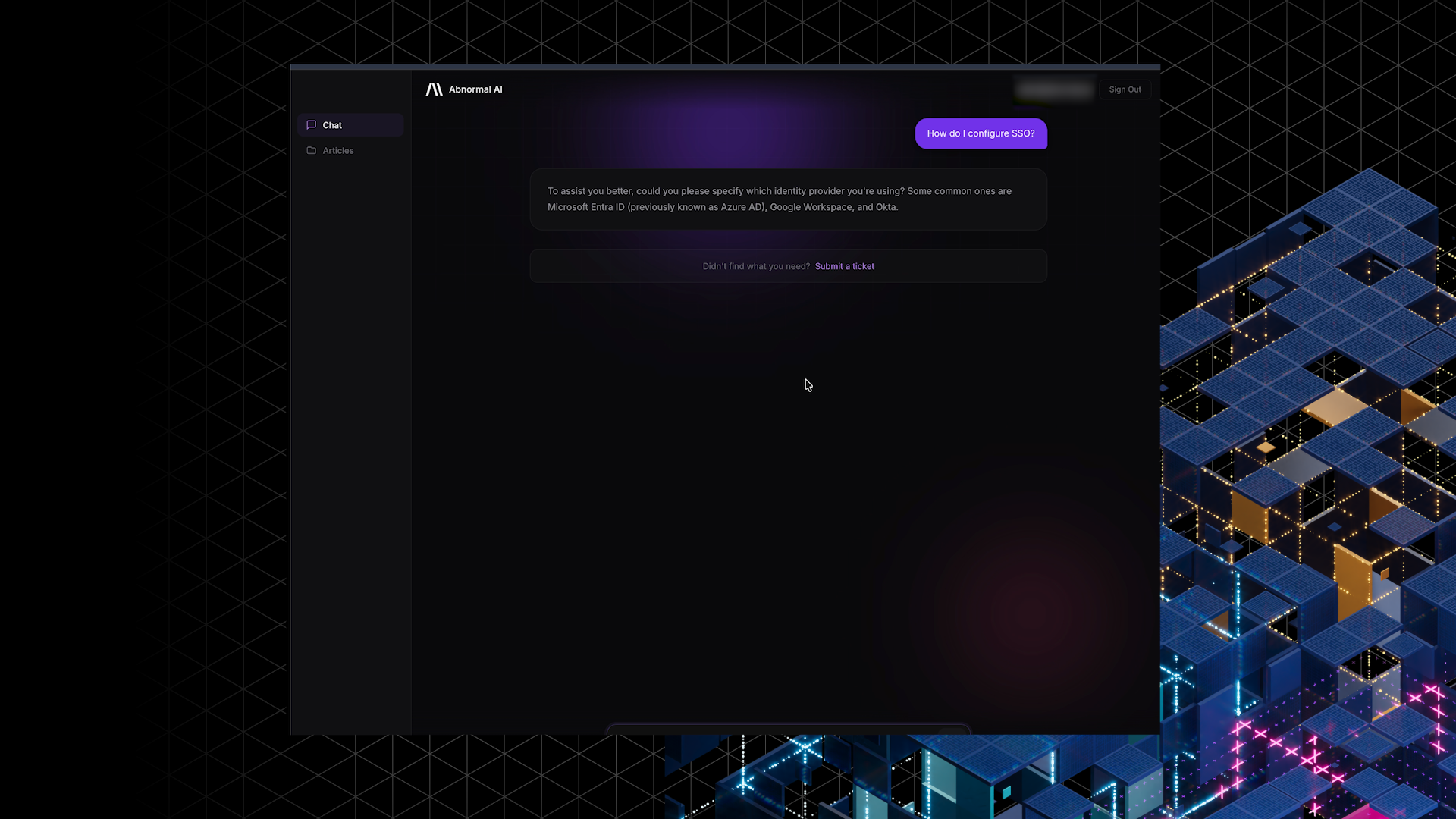
A Customer Bot You Can Run
Andres positioned help.abnormal.ai as Abnormal’s direct-to-customer conversational surface, now deployed on Vercel with a refreshed website UI and authentication. He also demoed what happens when things go wrong, including an explicit fallback when the underlying API key hits a usage limit. That honesty matters because customers will hit the edges first, not the happy path.
As Andres put it, “here’s the new UI for the website… and here’s the auth… you’re gonna see a fallback, for the API usage limits.”
What shipped in this installment:
- Refreshed help site UI designed for end-customer Q&A, not internal testing.
- Authentication flow to control access to support content and protect customer-facing materials.
- Ticket handoff via email generation with a “submit a ticket” action that packages the conversation into a draft.
- Conversation history logging is stored for review and iteration.
- Evaluation app that reads conversation histories (via Vercel Blob) and produces quality signals.
Instead of treating evaluation as an offline exercise, Andres connected it directly to product operations. The team can define what “resolution” means, track the resolution rate, run per-query quality auto-evals, and test the current prompt against a gold standard dataset.
Measuring What Customers Get
This demo sharpened the value proposition for two audiences: customers who need faster answers, and internal teams who need visibility into whether the bot is actually helping.
What improves with these updates:
- Customers: clearer UX with auth, plus a graceful path to Support when the bot cannot respond.
- Support and CS: fewer ambiguous tickets because the generated email can include the full conversation context.
- Product and Eng: measurable signals like resolution rate and query-level quality, grounded in real conversations.
Next step: complete the loop Andres outlined by clustering customer questions into topics and feeding the evaluation findings back into the bot's prompt and retrieval behavior, so performance improves with usage rather than drifting.
Turning Limits into Learnings
Peers zeroed in on the practical blocker: usage limits and how they shape what the team can do next. That reaction is useful because it reflects how the org will judge the project: not by a single great answer, but by consistent availability and clear iteration.
This installment also signals a cultural shift that fits Abnormal’s mission. The bot is becoming a product surface with instrumentation and accountability, and the team is building the muscle to learn from customer questions, group them, and systematically raise answer quality over time.
